blog-01에 HDD 1GB 추가
250M으로 4개 primary로 생성

필요한 패키지들

설치한 패키지들의 방화벽을 열어주고 /etc/exports안에 squash 옵션을 부여
# [Share Dir] [Allow Host/Network][(Option)]
/nfs_server1 192.168.1.150(rw,no_root_squash,sync)
/nfs_server2 192.168.1.0/24(rw,async,no_wdelay)
/nfs_server3 *(rw,all_squash,anonuid=1005,anongid=1005,sync)
/nfs_server4 192.168.1.150(rw,no_root_squash,sync)
// squash 옵션을 잘 모르면 절대로 사용하면 안 된다.. 보안상의 문제 때문에
// no_root_squash : 절대로 사용하면 안 되는 옵션
// * : 어디에서든 접속할 수 있는 명령어 -> 사용 안 하는 게 좋음

// portmapper 가 올라와 있어야 활성화된 것
// nlockmgr : 파일 시스템을 공유한 상태로 내부에 들어있는 데이터를 동시다발적으로 사용하는 환경이 만들어졌을 때 동시에 쓰기 작업을 사용하지 못하게 한다.
// nlockmgr 이 올라와야 한다.. 올라오지 않으면 안 된다.
// 동시다발적으로 쓰기 작업이 절대로 허용하면 안 된다. (무결성이 깨져버리기 때문)
EX) 데이터베이스

// /etc/exports를 편집할 상황이 생겼을 때 적용하려면 restart 해야 하지만 누군가가 데이터를 전송, 사용 중일 때 데이터 손실을 막기 위해 사용
// ra 서비스를 재시작하지 않아도 적용할 수 있는 명령어

// 공유 정보
// nfs_server1~4까지 모두 공유가 잘 된 상태
// (~~~~) 적용된 옵션 -> 기본값에 맞춰서 자동으로 세팅
// sync : 동기식 작업, 실시간 스트리밍 형식으로 데이터가 저장
// 동기식 작업 : 실시간 데이터 작업
// async : 비동기식 작업, 하나의 블록단위가 만들어지고 한 덩어리씩 데이터가 저장되는 형식
// 비동기식 작업 : 캐시 메모리에 버퍼 공간을 만들고 버퍼에 저장된 데이터가 단위 형태로 실제 nfs서버에 저장되는 작업
// 다중 쓰기 작업이 많이 발생한다 -> 비동기식 작업
// 다중 사용자가 동시다발적으로 쓰기 작업을 사용하지 않는다 -> 동기식 작업
// wdelay(write delay 쓰기 지연) : sync와 세트 (async – no_wdelay)
// hide : 다중 클라이언트 일 때 사용(단일 호스트 일 때는no host를 사용한다고 명시)
- 보통 hide사용
// no_subtree : 하위 트리를 보여주지 않는다.
// rw : 읽기 쓰기
// secure : port번호의 범위를 명시 102보다 낮은 녀석 OK (default)
// insecure : 1024보다 크거나 같은 port 범위를 명시
// client에서 NFS를 사용하려면 root_squash, no_root_squash가 있어야 한다.
// root_squash, no_root_squash : 두 개씩 들어가야 함
- 일반 사용자를 위한 매핑
- root계정으로 로그인하면 root가 되는 게 아니라 nfs_nobody계정으로 접근된다.
- nfs_nobody : 어떠한 권한도 없는 일반 사용자
// no_root_squash
- client root, server root를 매핑하겠다.
- 허가되지 않은 사용자(해커)가 내 root를 만들어서 server의 root에 접근하면 안 되기 때문에 사용하면 안 되는 옵션

// rpcbind를 켜준 후 portmapper 켜져 있는 것 확인

// blog-01에 있는 디렉터리 똑같이 생성

blog-01에서 mount 걸어준 후

blog-02에서 blog-01로 mount
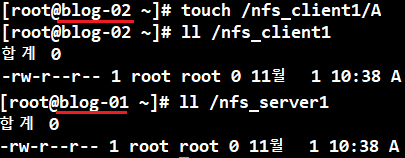
blog-02에서 생성한 파일이 blog-01에서도 생성되는 것 확인